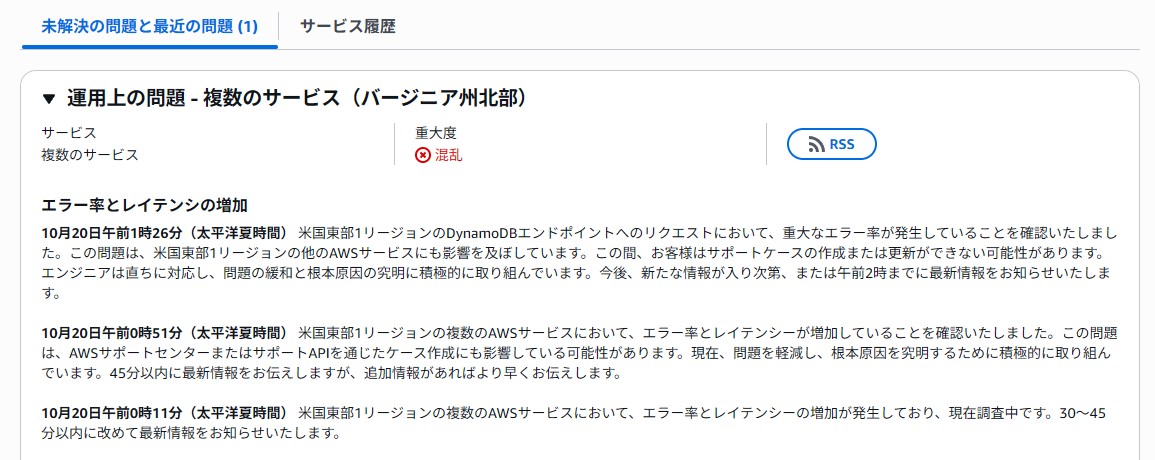
いただいた公式発表の情報を元に、何が原因だったのかを分かりやすく解説します。
結論から言うと、この障害の**根本的な原因は「ネットワークロードバランサーの状態を監視する、AWS内部の基盤システムに起きた不具合」**でした。
もう少し詳しく、障害の経緯を時系列で見ていきましょう。
### 障害の経緯と原因
この障害は、AWSの中でも特に重要な**「米国東部(バージニア北部)」リージョン(US-EAST-1)**で発生し、複数の原因が重なって段階的に深刻化したようです。
1. **【第1段階】 DNSの問題が発生(深夜1時頃〜)**
* 最初に、特定のサービス(DynamoDB)の名前解決を行う**DNS(※1)**に問題が発生しました。
* これにより、多くのサービスでエラーや遅延が起こり始め、AWSのサポート窓口に問い合わせができないといった影響も出ました。
* このDNSの問題自体は、数時間で修正されたと報告されています。
2. **【第2段階】 ネットワークシステムの不具合が判明(朝8時頃〜)**
* しかし、DNSの問題が解決した後も、広範囲なネットワーク接続の問題が続きました。
* 詳細な調査の結果、**「ネットワークロードバランサー(※2)の健全性をチェックする内部システム」**という、AWSの根幹を支える部分に不具合があることが特定されました。これが今回の障害の**根本原因**とされています。
### どんな影響があったか?
この根本原因により、以下のような深刻な影響が連鎖的に発生しました。
* **仮想サーバー(EC2)が起動できない**
* 新しい仮想サーバーを立ち上げる処理が多数失敗しました。復旧作業を優先するため、AWSは意図的に新規サーバーの立ち上げを制限する措置も取りました。
* **多くのAWSサービスが利用不能に**
* 仮想サーバーに依存している他の多くのサービス(データベース、コンテナサービスなど)も連鎖的に影響を受け、エラーが多発しました。
* **Lambda(※3)の実行エラー**
* サーバーレスでプログラムを実行できるLambdaでも、ネットワークの問題により多くのエラーが発生しました。
### まとめ
要するに、今回の障害は、**「AWSのネットワークの交通整理やサーバーの健康状態を監視する非常に重要な内部システムに不具合が生じ、それがドミノ倒しのように多くのサービスに影響を及ぼした」**ということになります。
提供された情報の最後の時点(午後1時52分)では、AWSが緩和策を講じ、サービスは回復に向かっていると報告されています。
---
**【用語の簡単な解説】**
* **※1 DNS:** インターネット上の住所録のようなもの。Webサイト名などを、コンピューターが通信に使うIPアドレスという番号に変換する仕組みです。
* **※2 ネットワークロードバランサー:** サービスへのアクセス(交通量)を複数のサーバーにうまく振り分け、1台に負荷が集中するのを防ぐ「交通整理役」です。
* **※3 Lambda:** サーバーの管理をすることなくプログラムコードを実行できる、便利なサービスです。